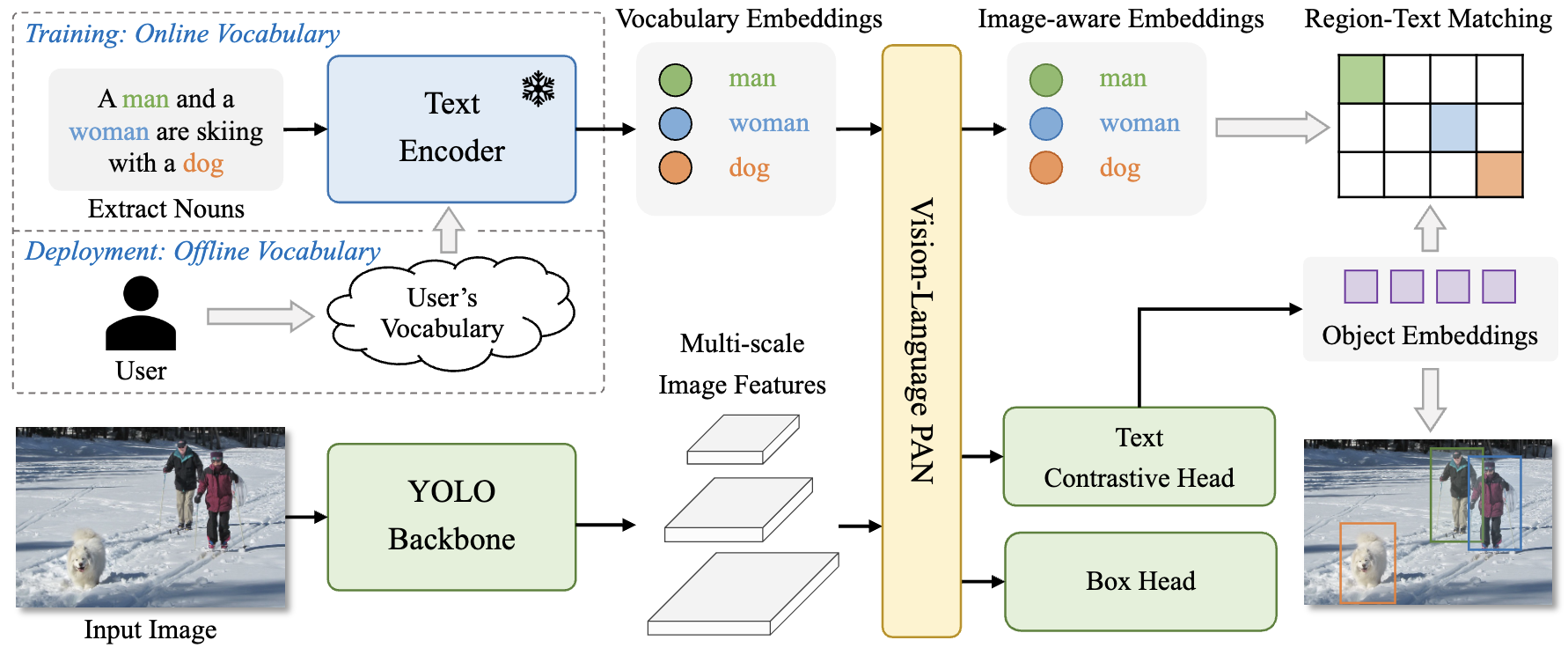
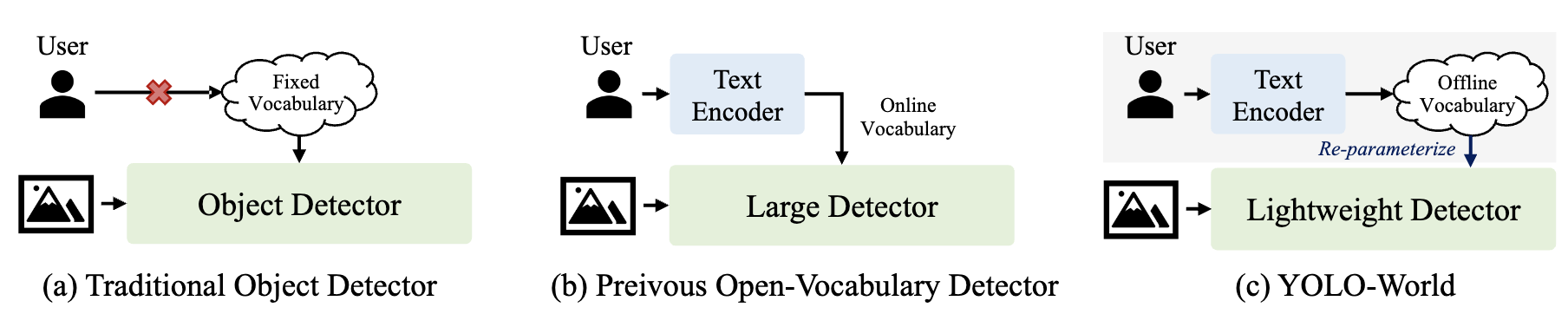
Open-vocabulary detection via vision-language modeling and pre-training on large-scale datasets.
Architecture
- YOLO Detector — YOLOv8
- Text Encoder — CLIP
- Text Contrastive Head — object-text similarity: $s_{k,j} = \alpha \cdot \text{L2-Norm}(e_k) \cdot \text{L2-Norm}(w_j)^T + \beta$
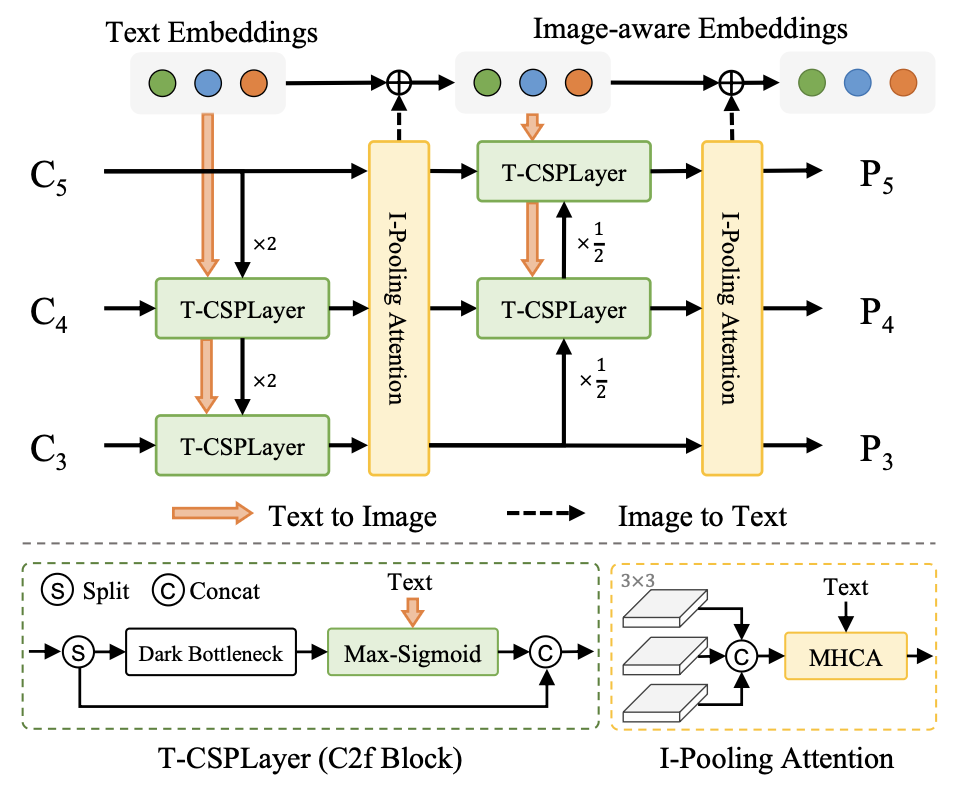
Re-parameterizable Vision-Language PAN (RepVL-PAN)
Text-guided CSPLayer
$X_l’ = X_l \cdot \delta(\max_{j \in {1..C}} (X_l W_j^T))$
Image-Pooling Attention
$W’ = W + \text{MultiHead-Attention}(W, \tilde{X}, \tilde{X})$
Training
$\mathcal{L}(I) = \mathcal{L}{con} + \lambda_I \cdot (\mathcal{L}{iou} + \mathcal{L}_{dfl})$
- $\lambda_I = 1$ for detection/grounding data, $0$ for image-text data