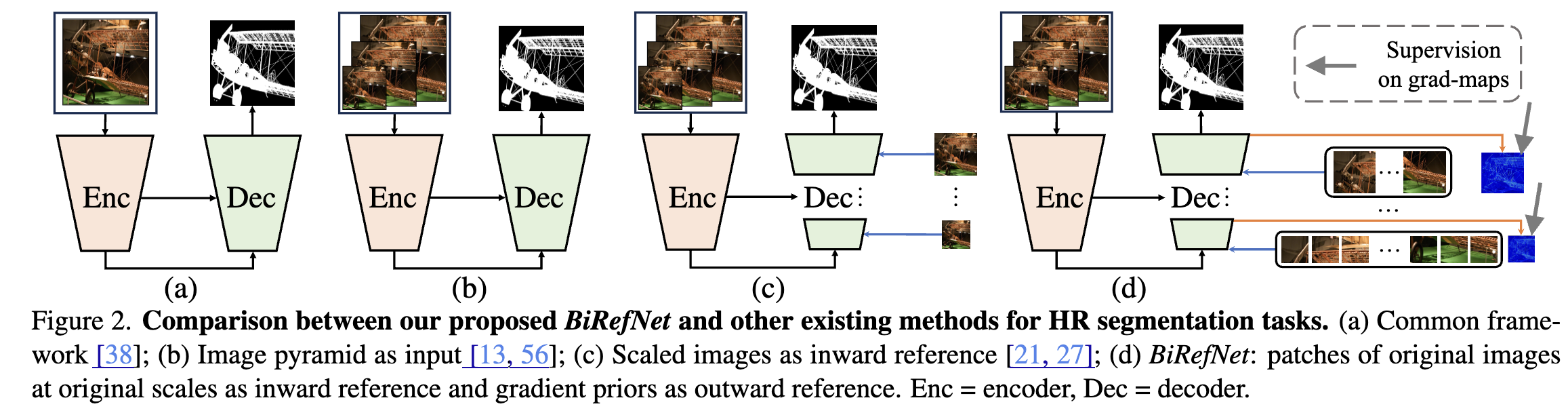
Bilateral Reference for High-Resolution Dichotomous Image Segmentation. Swin-Transformer based with inward reference (InRef) and outward reference (OutRef).
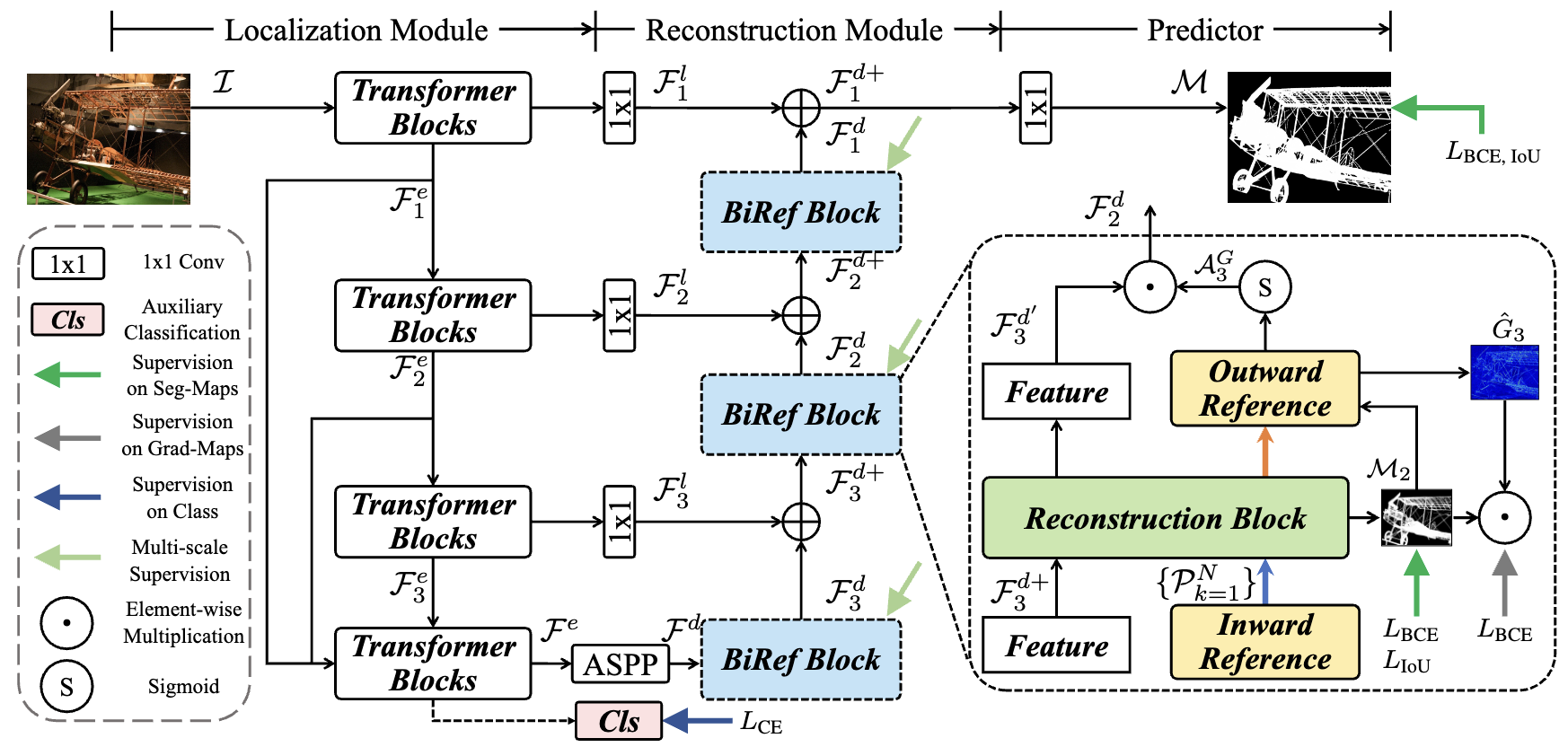
Two Essential Modules
Localization Module (LM)
- Transformer Encoder extracts features at different stages: $F_1^e, F_2^e, F_3^e$ with resolution at 4, 8, 16, 32
- First four features ${F_i^e}_{i=1}^3$ are transferred to corresponding decoder stages with lateral connections (1×1 convolution layers)
- Features are stacked and concatenated in the last encoder block to generate $F^e$, then fed into a classification module
- Uses Atrous Spatial Pyramid Pooling (ASPP) for multi-context fusion
Reconstruction Module (RM)
- Small receptive fields (RFs) lead to inadequate context; large RFs result in insufficient detail extraction
- Uses reconstruction block (RB) in each BiRef block as replacement for vanilla residual blocks
- Employs deformable convolutions with hierarchical RFs (1×1, 3×3, 7×7) and adaptive average pooling
- Features extracted by different RFs are concatenated as $F_i^{\theta}$, followed by 1×1 conv + batch norm → output $F_i^{d’}$
Bilateral Reference

- InRef (Inward Reference): Images $I$ with original high resolution are cropped to patches ${P_k}_{k=1}^N$ of consistent size with decoder stage output. Patches are stacked with original feature $F_i^{d+}$ and fed into RM.
- OutRef (Outward Reference): Gradient maps $G_i^{gt}$ draw attention to areas of richer gradient information. $F_i^{\theta}$ generates $F_i^G$ → predicted gradient maps $\hat{G}^i$ → gradient attention $A_i^G$ → multiplied by $F_i^{d’}$ → output $F_{i-1}^d$.