Dichotomous Image Segmentation — proposes IS-Net with 3 components:
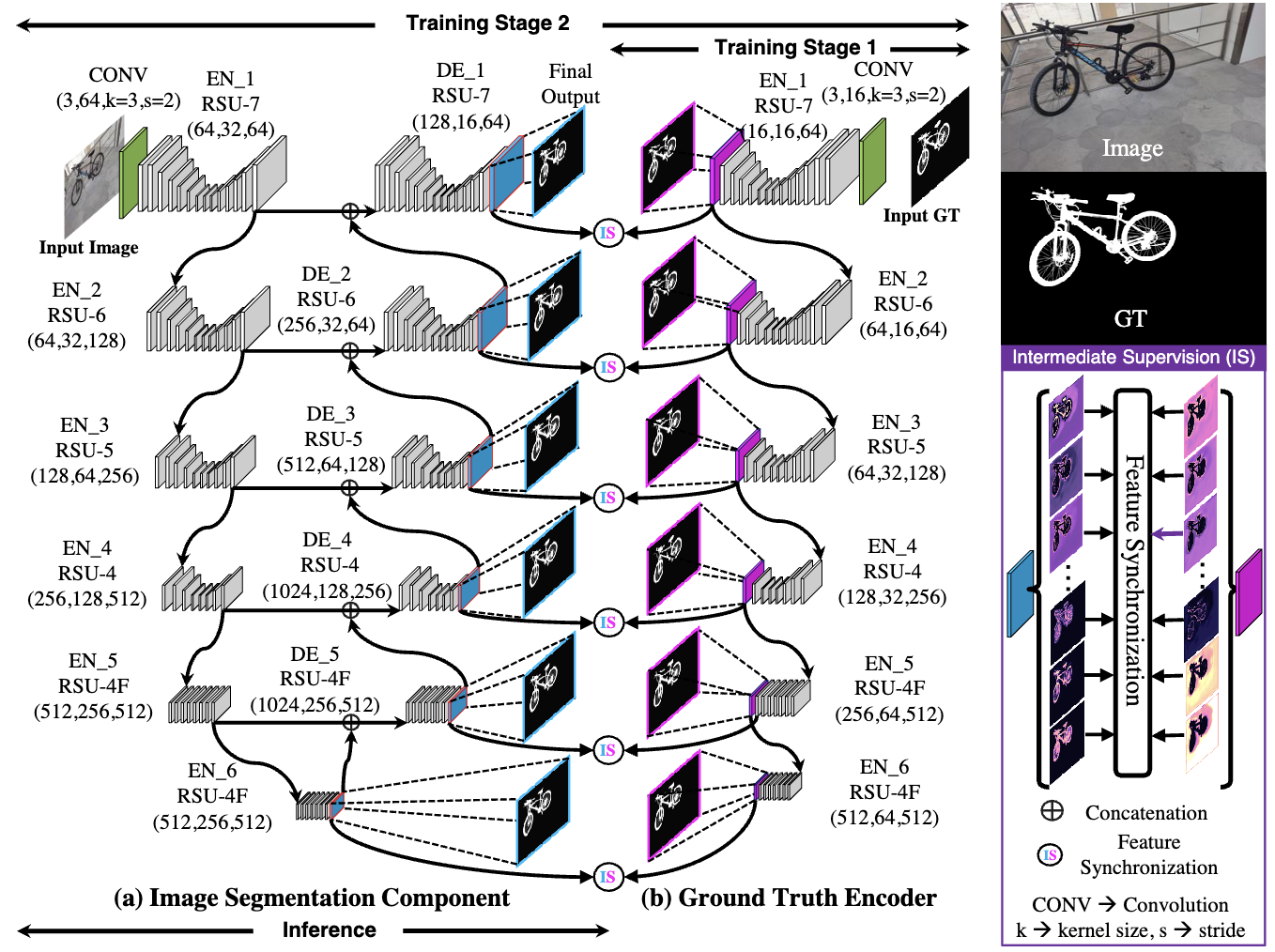
- Ground truth (GT) encoder
- Image segmentation component ($U^2$-Net based)
- Intermediate supervision strategy
Stage 1: Self-supervised GT Encoder Training
$L_{gt} = \sum_{d=1}^{D} \lambda_{d}^{gt} BCE(F_{gt}(\theta_{gt}, G)_d, G)$
GT encoder is frozen after this stage.
Stage 2: Feature Consistency
Feature Consistency Loss (intermediate supervision):
$L_{fs} = \sum_{d=1}^{D} \lambda_{d}^{fs} |f_{d}^{I} - f_{d}^{G}|^2$
$L_{sg} = \sum_{d=1}^{D} \lambda_{d}^{sg} BCE(F_{sg}(\theta_{sg}, I), G)$
Total loss: $L = L_{fs} + L_{sg}$
Results
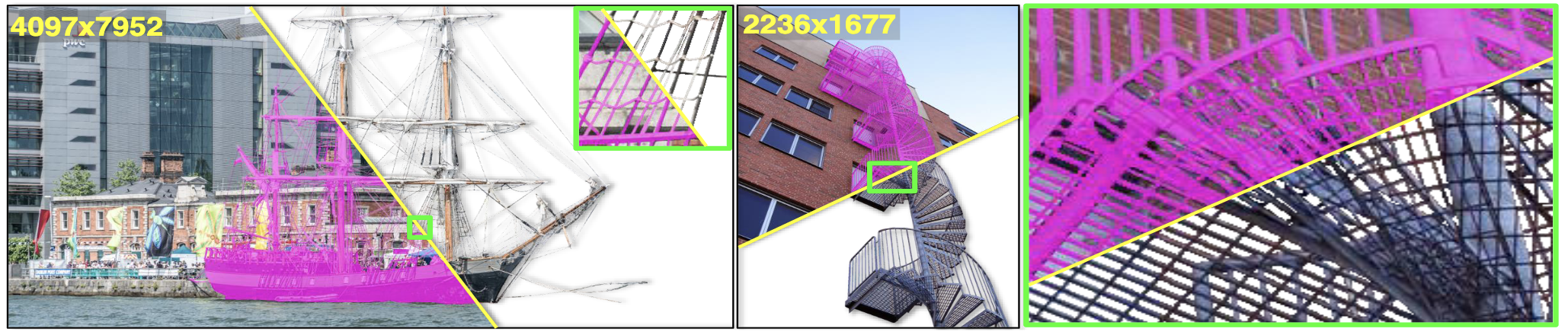
Metric: Human Correction Efforts (HCE)
